
This is a post I wrote for O'Reilly back in January 2003 when the SQL Slammer worm hit. It seems it's gone from their site now, so I'm putting it here, including the comments.
Read the article - posted 2003-01-28
As promised, some more information on the denial of service attacks on the root DNS servers last october. Paul Vixie, Gerry Sneeringer and Mark Schleifer prepared an event report with some good factual information. It seems each server received 50 to 100 Mbps worth of traffic, but not just ICMP as earlier reports indicated. The source addresses in the attacking IP packets were faked, but not easily identifiable as such. This explains why the attacking traffic wasn't simply filtered out very quickly.
However, all the "users weren't affected" and "the system kept running as designed" claims not withstanding, the fact that a fairly moderate amount of DoS traffic was able to make several of the root servers unreachable for many people is cause for concern. It seems the root server operators have picked up on this and are working on solutions. However, they're not saying much about this, which in itself is also cause for concern... "Security by obscurity" doesn't have a very good track record.
Permalink - posted 2003-02-14
I think I'm jinxed. When I put my anti-DoS article up on this site the root name servers were attacked. Then O'Reilly put the article on ONLAMP and the next day there was the MS SQL worm...
A worm in a single 404 byte UDP packet: the net certainly wasn't prepared for that. This worm didn't really harm infected systems all that much: it's the incredible amount of traffic generated by each infected system that caused so much trouble. Obviously dozens of megabits worth of traffic for each affected host will lead to congestion in many places, but it was worse than that: Cisco routers that were doing fast switching rather than Cisco Express Forwarding (CEF) ran out of memory and CPU. It also seems Riverstone routers, which are supposed to be able to do this in hardware, fell flat on their faces. (But I haven't seend this myself.)
Have a look at an article I wrote for the O'Reilly Network about the impact of this worm: Network Impact of the MS SQL Worm. (Note: the link doesn't work anymore, but I saved the article here.) And CAIDA has an in-depth analysis.
Permalink - posted 2003-02-14
The Faculty of Math and Physics of the Charles University in Prague has created BGP capable routing software for Unix machines released under the GNU General Public License. The BIRD Internet Routing Daemon supports multiple tables with BGP and RIP for both IPv4 and IPv6 and OSPF for IPv4.
Permalink - posted 2003-02-16
Data Connection has a full range of routing products, including the BGP, OSPF and IS-IS protocols. BGP has support for VPNs. The software is very portable and should run on pretty much anything, from Solaris to Windows to special environments, with very little porting effort.
Permalink - posted 2003-02-16
A company called Packet Design has developed BGP Scalable Transport (BST), a transport protocol for BGP that is intended to replace TCP as the carrier potocol for BGP routing information. Packet Design isn't afraid to make bold claims; their press release about the protocol heads "Packet Design solves security, reliability problems of major internet routing protocol, BGP."
But BST really only addresses the problem that each BGP router in an organization is required to talk to every other BGP router. This gets out of hand very fast in larger networks. But two solutions have been around for years: route reflectors and confederations. When a BGP router is configured to be a route reflector, it checks for routing loops so it can safely "reflect" routing information from one router to another, eliminating the need to have every two routers communicate directly. Confederations break up large Autonomous Systems (ASes) into smaller ones and accomplish the same thing in a different way. Packet Design solves the problem by flooding BGP updates throughout the internal network, much the same way protocols such as OSPF and IS-IS do.
Packet Design claims that this will help with convergence speed and reliability and even security. Their reasoning is that using IPsec on lots of individual TCP sessions uses too much CPU so protecting BGP over TCP with IPsec is unfeasible. But even on a Pentium II @ 450 MHz with SHA-1 authentication you get 17 Mbps (see performance tests). Exchange of a full routing table takes about 8 MB and 1 minute = around 1 Mbps so with less than 17 peers receiving a full table the crypto can keep up without trouble. And that's even assuming internal BGP sessions need this level of protection. External BGP sessions are a more natural candidate for this but eBGP doesn't have the same scalability problem as iBGP. It also assumes the security problems BGP has can be fixed at the TCP level. However, the most important BGP vulnerability is that there is no scalable and reliable way to check whether the origin of a BGP route is allowed to send out the route in question to begin with and whether any information was changed en route (by on otherwise legitimate intermediate router). These issues are addressed by soBGP and S-BGP.
Permalink - posted 2003-02-19
RIPE has another analysis of the MS SQL worm. RIPE monitors performance between 49 locations on the net. 40% of the monitored pairs of hosts suffered from congestion between them, in 60% of the cases there weren't any problems. The problems were cleared up after about 8 hours.
RIPE also monitors root server performance and BGP activity. Two of the root servers suffered a good deal of packet loss. The BGP stuff is the most spectacular: there were about 30 to 60 times more updates of different kinds.
This clearly shows the need for control and data plane seperation: congestion in the actual traffic shouldn't be able to take down the routing protocols. On the other hand, having BGP and other routing protocols run "in-band" over the same circuits as the actual data makes sure there is a functioning path between two routers. There's also something to be said for that.
On NANOG there was some talk about UDP/1434 filters. I argued that they shouldn't be necessary any more by now, but the rate of reinfection (people bringing in new vulnerable boxes) remains significant. So places with Windows machines on the network will probably need to have these filters in place for the forseeable future. But this is annoying because they also block legitimate UDP traffic, such as DNS, once in a while, and many routers take a performance hit when these types of filters are enabled.
Permalink - posted 2003-02-27
(Distributed) Denial of Service attacks continue to be a serious problem. (Well, for the victims, at least.) RIPE suffered an attack on februari 27th 2003 that almost wiped them off the net for two and a half hours.
Permalink - posted 2003-04-10
On august 7th 2002, Rob Thomas announced on his bogon list and a number of mailinglists that IANA had delegated the 69.0.0.0/8 address block to APNIC for further distribution to ISPs and end-user organizations in the Asia-Pacific region. The next day, APNIC made an announcement of their own.
Exactly seven months later, someone who had gotten addresses in the new range posted a message to the NANOG under the title "69/8...this sucks". He encountered problems reaching certain destinations from the new addresses and wrote a script to test this. It turned out a significant number of sites ("dozens") still filtered this range.
Further investigation uncovered that this wasn't so much a routing problem, but many firewall administrators also use the bogon list to create filters. And then subsequently fail to keep those filters up to date.
This sucks indeed.
Permalink - posted 2003-04-10
If your network has a link with an MTU that's smaller than 1500 bytes in the middle, you're in trouble. It's not the first time this came up on the NANOG list and it won't be the last.
In order to avoid wasting resources by either sending packets that are smaller than the maximum supported by the network or sending packets that are so large they must be fragmented, hosts implement Path MTU Discovery (PMTUD). By assuming a large packet size and simply transmitting them with the don't fragment (DF) bit set (in IPv4, in IPv6 DF is implied) and listening for ICMP messages that say the packet is too big, hosts can quickly determine the lowest Maximum Transmission Unit (MTU) that's in effect on a certain link.
Most of the time, that is. In RFC 1191 it is suggested that hosts quickly react to a changing path MTU. So implementors decided to simply set the DF bit on ALL packets. At the same time, many people are very suspicious of ICMP packets since they can be used in denial of service attacks or to uncover information about a network. So to be on the safe side a significant number of people filters all ICMP messages. Or routers are configured in such a way that the ICMP packet too big messages aren't generated or can't make it back to the source host. NAT really doesn't help in this regard either.
So what happens when all packets have DF set and there are no ICMP packet too big messages? Right: nothing. Since the first few packets in a session are typically small session get set up without problems but as soon as the data transfer starts the session times out. So what can we do?
RFC 2923 TCP Problems with Path MTU Discovery
The MSS Initiative
Cisco - Why Can't I Browse the Internet when Using a GRE Tunnel?
Permalink - posted 2003-05-19
Geoff Huston, member of the Internet Architecture Board, wrote as one of his monthly columns for the Internet Society Waiting for IP version 6. In this column Geoff argues that the only real advantage IPv6 has over IPv4 are the larger addresses, but we are not very close to running out of IPv4 address space yet with 1.5 billion addresses still unallocated. So he expects demand for IPv6 will not be driven by anything or anyone that's online now but rather by the tons of new devices that need connectivity in the future.
The IPv6 Forum doesn't quite agree and, in the persons of Latif Ladid and Jim Bound, sent in a response. They argue IPv6 does have some additional features that make it better than IPv4, such as the flow label, for which there is currently no use defined but it could help quality of service efforts, stateless autoconfiguration and routing scalability. They do have a point here.
Sure, in IPv4 you can use DHCP and you're online without having to configure an address and additional parameters. However, there must still be a DHCP server somewhere. These days, DHCP servers are built in pretty much anything that can route IP or perform NAT. This works quite well for numbering hosts that act as clients, but it doesn't really help with servers because in order to have a DHCP server give out stable addresses it must be configured to do so. This is only slightly better than having to configure the host itself. In IPv6, this is only a problem in theory. IPv6 stateless autoconfiguration makes a host select the same address for itself each time, without the need to configure this address either on the host or on a DHCP server. The theoretical problem is that some other host may select the same address because of MAC address problems (as the lower part of the address is derived from the MAC address) but this should be extremely rare.
Routing is the same for IPv6 as for IPv4. Both use provider aggregation to limit the number of routes in the global routing table. However, address conservation in IPv4 makes it necessary to make these provider blocks much smaller than is desirable from a routing aggregation standpoint. In IPv4, ISPs get /20 blocks and only the ones using up address space really fast get /16 blocks. In IPv6, every ISP gets at least a /32 and the next seven /32s remain unallocated so this can grow to a /29 (at least in the RIPE region) so ISPs need far fewer individual blocks to assign address space to their customers. This should help with route scaling. Unfortunately, it doesn't help with customers who are multihomed. But that's another story.
Permalink - posted 2003-05-23
This friday the 13th (of june 2003), John Stenbit, assisten secretary of defense, announced that the US Department of Defense will start its transition to IPv6 this october. The DoD expects to be fully IPv6-capable by 2008. The reasons to switch to IPv6 are:
The transition is not driven by lack of IPv4 address space. However, there is no fundamental difference in QoS and security mechanisms between IPv6 and IPv4, apart from the flow label field in IPv6 for which there isn't really a use yet, so these are questionable reasons to move to IPv6. The DoD expects switching to IPv6 in the commercial internet (or at least significant parts thereof) to happen at a faster rate, so in order to keep up the DoD is taking a head start.
The DoD initiative was met with approval on the IETF discussion list, although some people remain sceptical as past announcements, such as the adoption of the ADA programming language or ISO CLNS didn't exactly pan out. Still, reading the transcipt of the briefing the DoD seems to mean business by requiring all IP-capable hard- and software procured after october first to support IPv6.
Permalink - posted 2003-06-15
In an article for the Australian Commsworld site, Juniper's Jeff Doyle explains his views on the need for IPv6. He has little patience with the scare tactics some IPv6 proponents use, but rather argues that IPv6 is simply progress and it will be cheaper to administrate in the long run.
Permalink - posted 2003-08-03
The SANS (SysAdmin, Audit, Network, Security) Institute has published Is The Border Gateway Protocol Safe?. a paper (PDF) on different security aspects of BGP. Nothing groundbreaking, but detailed an a good read for people with a sysadmin background.
Permalink - posted 2003-08-03
Yet another worm analysis article: Effects of Worms on Internet Routing Stability on the SecurityFocus site. This one covers Code Red, Nimda and the SQL worm. No prizes for guessing which had the most impact on the stability of the global routing infrastructure.
Yes, it's old news, unlike Cisco's latest vulnerability (which just seems like very old news) but this stuff isn't going away and we have to deal with it. Are your routers prepared for another one of these worms?
Permalink - posted 2003-08-03
At the Network and Distributed System Security Symposium 2003 (sponsored by the NSA), a group of researchers from AT&T Labs Research (and one from Harvard) presented a new approach to increasing interdomain routing security. Unlike Secure BGP (S-BGP) and Secure Origin BGP (soBGP), this approach carefully avoids making any changes to BGP. Instead, the necessary processing is done on an external box: the Interdomain Routing Validator that implements the Interdomain Routing Validation (IVR) protocol. The IRV stays in contact with all BGP routers within the AS and holds a copy of the AS's routing policy. The idea is that IRVs from different ASes contact each other on reception of BGP update messages to check whether the update is valid.
See the paper Working Around BGP: An Incremental Approach to Improving Security and Accuracy of Interdomain Routing in the NDSS'03 proceedings for the details. It's a bit wordy at 11 two column pages (in PDF), but it does a good job of explaining some of the BGP security problems and the S-BGP approach in addition to the IRV architecture.
This isn't a bad idea per se, however, the authors fail to address some important issues. For instance, they don't discuss the fact that routers only propagate the best route over BGP, making it impossible for the IVR to get a complete view of all incoming BGP updates. They don't discuss the security and reliability implications of having a centralized service for finding the IRVs associated with each AS. Last but not least, there is no discussion of what exactly happens when invalid BGP information is discovered.
The fact that that peering policies are deemed potentiallly "secret" more than once also strikes me as odd. How exactly are ISPs going to hide this information from their BGP-speaking customers? Or anyone who knows how to use the traceroute command, for that matter?
Still, I hope they'll bring this work into the IETF or at least one of the fora where interdomain routing operation is discussed, such as NANOG or RIPE.
Permalink - posted 2003-08-10
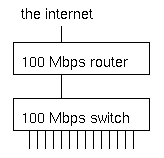
What's wrong with this picture?
Under normal circumstances, not much. But when several machines are infected with an aggressive worm or participating in a denial of service attack when an attacker has compromised them, the switch will receive more traffic from the hosts that are connected to the 100 Mbps ports than it can transmit to the router, which also has a 100 Mbps port.
The result is that a good part of alll traffic is dropped by the switch. This doesn't matter much to the abusive hosts, but the high packet loss makes it very hard or even impossible for the other hosts to communicate over the net. We've seen this happen with the MS SQL worm in january of this year, and very likely the same will happen on august 16th when machines infected with the "Blaster" worm (who comes up with these silly names anyway?) start a distributed denial of service attack on the Windows Update website. Hopefully the impact will be mitigated by the advance warning.
So what can we do? Obviously, within our own networks we should make sure hosts and servers aren't vulnerable, not running and/or exposing vulnerable services and quickly fixing any and all infections. However, for service or hosting providers it isn't as simple, as there will invariably be customers that don't follow best practices. Since it very close to impossible to have a network without any places where traffic is funneled/aggregated, it's essential to have routers or switches that can handle the full load of all the hosts on the internal network sending at full speed and then filter this traffic or apply quality of service measures such as rate limiting or priority queuing.
This is what multilayer switches and layer 3 switches such as the Cisco 6500 series switches with a router module or Foundry, Extreme and Riverstone router/switches can do very well, but these are obviously significantly more expensive than regular switches. It should still be possible to use "dumb" aggregation switches, but only if the uplink capacity is equal or higher than the combined inputs. So a 48 port 10/100 switch that connects to a filter-capable router/switch with gigabit ethernet, could support 5 ports at 100 Mbps and the remaining 43 ports at 10 Mbps. In practice a switch with 24 or 48 100 Mbps ports and a gigabit uplink or 24 or 48 10 Mbps ports with a fast ethernet uplink will probably work ok, as it is unlikely that more than 40% or even 20% of all hosts are going to be infected at the same time, but the not uncommon practice of aggregating 24 100 Mbps ports into a 100 Mbps uplink is way too dangerous these days.
Stay tuned for more worm news soon.
Permalink - posted 2003-08-14
The power outage in parts of Canada and the US a little over a week ago didn't cause too many problems network-wise. (I'm sure the people who were stuck in elevators, had to walk down 50 flights of stairs or walk from Manhattan to Brooklyn or Queens have a different take on the whole thing.) The phone network in general also experienced problems, mostly due to congestion. The cell phone networks were hardly usable.
There was a 2% or so decline in the number of routes in the global routing table. The interesting thing is that not all of the 2500 routes dropped off the net immediately, but some did so over the course of three hours. This would indicate depleting backup power.
See the report by the Renesys Corporation for more details.
Following the outage there was (as always) a long discussion on NANOG where several people expressed surprise about how such a large part of the power grid could be taken out by a single failure. The main reason for this is the complexity in synchronizing the AC frequencies in different parts of the grid. Quebec uses high voltage direct current (HVDC) technology to connect to the surrounding grids, and wasn't affected.
In the mean time the weather in Europe has been exceedingly hot. This gives rise to cooling problems for many power plants as the river water that many of them use gets too warm. In Holland, power plants are allowed to increase the water temperature by 7 degrees Celsius with a maximum outlet temperature of 30 degrees. But the input temperature got as high as 28 degrees in some places. So many plants couldn't work at full capacity (even with temporary 32 degree permits), while electricity demand was higher than usual, also as a result of the heat. (The high loads were also an important contributor to the problems in the US and Canada as there was little reserve capacity in the distribution grids.) The plans for rolling blackouts were already on the table when the weather got cooler over the last week.
Moral of these stories: backup power is a necessity, and batteries alone don't hack it, as the outage lasted for three days in some areas.
Permalink - posted 2003-08-24
The worm situation seems to be getting worse, but fortunately worm makers fail to exploint the full potential of the vulnerabilities they use. For instance, we were all waiting to see what would happen to the Windows Update site when the "MS Blaster" worm was going to attack it on august 16th. But nothing happened. I read that Microsoft took the site offline to avoid problems, having no intention to bring it back online again, but obviously this information was incorrect because they're (back?) online now.
However, Microsoft received help from another worm creator who took it upon him/herself to fix the security hole that Blaster exploits, by first exploiting the same vulnerability, then removing Blaster and finally downloading Microsoft's patch. But in order to help scanning, the new worm (called "Nachi") first pings potential target, leading to huge ICMP floods in some networks, although others didn't see much traffic generated by the new worm. Nachi uses an uncommong ICMP echo request packet size of 92 bytes, which makes it possible to filter the worm without having to block all ping traffic. See Cisco's recommendations. It seems TNT dial-up concentrators have a hard time handling this traffic and reboot periodically. The issue seems to be lack of memory/CPU to cache all the destinations the worm tries to contact, just like what happened with the MS SQL worm earlier this year and others before it.
Then there's the Sobig worm. This one uses email to spread, which has two advantages: the users actually see the worm so they can't ignore the issue and the network impact is negligible as the spread speed is limited by mail server capacity. Unfortunately, this one forges the source with email addresses found on the infected computer, which means "innocent bystanders" receive the blame for sending out the worm. Interestingly enough, I haven't received a single copy of either this worm or its backscatter so far, even though it seems to be rather aggressive, many people report receiving lots (even thousands) of copies.
Then on friday there was a new development as it was discovered that Sobig would contact 20 IP addresses at 1900 UTC, presumably to receive new instructions/malicious code. 19 of the addresses were offline by this time, and the remaining one immediately became heavily congested. So far, nobody has been able to determine what was supposed to happen, but presumably, it didn't.
There was some discussion on the NANOG list about whether it's a good idea to block TCP/UDP ports to help stop or slow down worms. The majority of those who posted their opinion on the subject feel that the network shouldn't interfere with what users are doing, unless the network itself is at risk. This means temporary filters when there is a really aggressive worm on the loose, but not permanently filtering every possible vulnerable service. However, a sizable minority is in favor of this. But apart from philosophical preferences, it makes little sense to do this as the more you filter, the bigger the impact for legitimate users, and it has been well-established that worms manage to bypass filters and firewalls, presumably through VPNs or because people bring in infected laptops and connect them to the internal network.
Something to look forward to: with IPv6, there are so many addresses (even in a single subnet) that simply generating random addresses and see if there is a vulnerable host there isn't a usable approach. On the other hand, I've already seen scans on a virtual WWW server which means that the scanning happened using the DNS name rather than the server's IP address, so it's unlikely that the IPv6 internet will remain completely wormfree, even if things won't be as bad as they're now in IPv4.
Permalink - posted 2003-08-24
This week there is the RIPE 46 meeting, once again in Amsterdam. Note that if you can't attend, you can follow what's happening using the experimental streaming service. The streaming bandwidth is around 225 kbps for the highest quality but you can fall back to lower quality or audio only, I think. It works both with Windows Mediaplayer and Video Lan Client on my Mac.
There are also archives of the streamed sessions. The presentation slides are also generally available.
Permalink - posted 2003-09-01
There are now VoIP phones that cost about 60 - 75 dollars/euros and there is the free Asterisk "Open Source Linux PBX" software.
Unfortunately, the room didn't seem all that receptive. Well, too bad. I guess the routing crowd isn't ready for IPv6 stuff in general and somewhat non-mainstream IPv6 stuff in particular.
After that there was an hour-by-hour account from a Cisco incident response guy (Damir Rajnovic) about the input queue locking up vulnerability that got out in june. It seems they spend a lot of time keeping this under wraps. I'm not sure if I'm very happy about this. One the one hand, it gives them time to fix the bug, on the other hand our systems are vulnerable without us knowing about it. They went public a day or so earlier than they wanted because there were all kinds of rumours floating around. It turned out that keeping it under wraps wasn't entirely a bad idea as there was an exploit within the hour after the details got out. But I'm not a huge fan of them telling only tier-1 ISPs that "people should stay at the office" and then disclosing the information to them first. It seems to me that announcing to everyone that there will be an announcement at some time 12 or 24 hours in the future makes more sense. In the end they couldn't keep the fact that something was going on under wraps anyway. And large numbers of updated images with vague release notes also turned out to be a big clue to people who pay attention to such things. One thing was pretty good: it seems that Cisco itself is now working on reducing the huge numbers of different images and feature sets, because this makes testing hell.
Permalink - posted 2003-09-01
Yesterday's presentation in the routing wg about bidirectional forwarding detection (that I completely forgot about during all the train rerouting) was much more interesting. Daves Katz and Ward wrote an Internet Draft draft-katz-ward-bfd-01.txt for a new protocol that makes it possible for routers to check whether the other side is still forwarding. This goes beyond the link keepalives that many protocols employ, because it also tests if there is any actual forwarding happening. And the protocol works for unidrectional links and to top it all off, it works at millisecond granularity. There is a lot of interest in this protocol, so there is considerable pressure to get it finished soon.
But wednesday's routing session wasn't a complete write-off as Pascal Gloor presented the Netlantis Project. This is a collection of BGP tools. Especially the Graphical AS Matrix Tool is pretty cool: it shows you the interconnections between ASes. I'm not exactly sure how it decides which ASes to include, but it still provides a nice overview.

Kurtis Lindqvist presented an IETF multi6 wg update.
Gert Doering talked about the IPv6 routing table. Apart from the size, there are some notable differences with IPv4: IPv6 BGP interconnection doesn't reflect business relationship or anything close to physical topology: people are still giving away free IPv6 transit and tunneling all over the place. This is getting better, though. (The problem with this is that you get lots of routes but no way to know in advance which are good. Nice to have free transit, not so nice when it's over a tunnel spanning the globe.) There are now nearly 500 entries in the global IPv6 table, which is nearly twice as much as two years ago. About half of those are /32s from the RIRs (2001::/16 space), and the rest more or less equally distributed over /35s from the RIRs and /24s, /28s and /32s from 6bone space (3ffe::/16).
I'm not sure if it was Gert, but someone remarked during a presentation: "In Asia, they run IPv6 for production. In Europe, they run it for fun. In the US, they don't run it at all."
Jeroen Massar talked about "ghost busting". When the Regional Internet Registries started giving out IPv6 space, they assigned /35s to ISPs. Later they changed this to /32s. The assignments were done in such a way that an ISP could simply change their /35 announcement to a /32 announcement "in place". However, this is not entirely without its problems as the BGP longest match first rule dictates that a longer prefix is always preferred (such as a /35 over a /32), regardless of the AS path length or other metrics. With everyone giving away free transit, there are huge amounts of potential longer paths that BGP will explore before the /35 finally disappears from the routing table and the /32 is used.
To add insult to injury, there appear to be bugs that make very long AS paths stay around when they should have disappeared. These are called "ghosts" so hence the ghost busting. See the Ghost Route Hunter page for more information.
Permalink - posted 2003-09-16
At the end of the thursday plenary at the RIPE 46 meeting, Geoff Huston presented IPv4 Address Lifetime Expectancy Revisited (PDF).

If looking at the slides leaves you puzzled, have a look at one of Geoff's columns from a few months ago that (as always) explains everything both in great detail and perfect clarity: IPv4 - How long have we got? (The full archive is available at http://www.potaroo.net/papers.html.)
Geoff looks at three steps in the address usage process:
It looks like the free IANA space is going to run out in 2019. But the RIRs hold a lot of address space in pools of their own, if we include this the critical date becomes 2026. Initially, projections of BGP announcements would indicate that all the regularly available address space would be announced in 2027, and if we include the class E (240.0.0.0 and higher) address space a year later. However, Geoff didn't stop there. After massaging the data, his conclusion was that the growth in BGP announcements doesn't seem exponential after all, but linear. With the surprising result:
"Re-introducing the held unannounced space into the routing system over the coming years would extend this point by a further decade, prolonging the useable lifetime of the unallocated draw pool until 2038 - 2045."
Now of course there are lots of disclaimers: whatever happened in the past isn't guaranteed to happen in the future, that kind of thing. This goes double for the BGP data, as this extrapolation is only based on three years of data. But still, many people were pretty shocked. It was a good thing this was the last presentation of the day, because there were soon lines at the microphones.
So what gives? Ten years ago the projections indicated that the IPv4 address space would be depleted by 2005. Now, an internet boom and large scale adoption of always-on internet access later, it isn't going to be another couple of years, but four decades? Seems unlikely. Obviously CIDR, VLSM, NAT and ethernet switching that allows much larger subnets have all slowed down address consumption. But I think there are some other factors that have been overlooked so far. One of those is that some of the old assignments (such as entire class A networks) are being used up right now. For instance, AT&T Worldnet holds 12.0.0.0/8, but essentially this space is used much like a RIR block, ranges are further assigned to end-users. We're probably also seeing big blocks of address space disappearing from the global routing table because announcing such a block invites too much worm scanning traffic. On the other hand there are also reports from "ISPs" that assign private address space to their customers and use NAT. So I guess there is a margin of error in both directions.
The the same time, the argument can be made that for all intents and purposes the IPv4 address space has already run out: it's way too hard to get the address space you need (let alone want). This is in line with what Alain Durand and Christian Huitema explain in RFC 3194. They argue that the logarithm of the number of actually used addresses divided by the logarithm of the number of usable addresses (the HD ratio) represents a pain level: below a ratio of 80% there is little or no pain, trouble starts at 85% and 87% represents a practical maximum. For IPv4 that would be 211 million addresses used (note that in the RFC the number is 240 million, but this is based on the full 32 bits while a little over an eighth of that isn't usable).
According to the latest Internet Domain Survey we're now at 171 million. This is counting the number of hosts that have a name in the reverse DNS, so the real number is probably higher.
I think RFC 3194 is on the right track but rather than simply do a log over the size of the address space, what we should look at is the number and flexibility of aggregation boundaries. In the RFC phone numbers are cited. Those have one aggregation boundary: area code vs local number, with a factor 10 flexibility. This means wasting a factor 10 (worst case) once. Classful IPv4 also had a single boundary, but the jumps are 8 bits, so a waste of a factor 256. With classless IPv4 we have more boundaries, but they're only one bit most of the time: IANA->RIRs, RIR->ISPs, ISP->customers and subnet. That's four times a factor two, so a factor 16 in total. That means we can use 3.7 billion addresses / 16 = 231 million IPv4 addresses without pain. Hm... But we can collapse some boundaries to achieve better utilization.
Permalink - posted 2003-09-16

Image link - posted 2003-10-03
Currently, there are very few people who want to run an IPv6-only network. And that's a good thing too, as presently, there is no way to do this. One of the big hurdles is the DNS. Right now, very few, if any, top level domains accept IPv6 glue records. However, there are no technical reasons why those can't be added. Unfortunately, there is a technical reason why making the existing root nameservers perform their function over IPv6 is problematic. When a nameserver starts up, it looks at a local file for root servers. However, it will only use this list of root servers for a single query: one that results in the list of current root servers. In order to avoid problems, it's important that the answer for this query contains all the addresses for the root servers as additional information. The problem is that the original DNS specifications allow a relatively short packet size (around 512 bytes). This allows for the current 13 root servers and their IPv4 addresses with little room to spare.
But in the mean time some root server operators are experimenting with making the root service available over IPv6. (See http://www.root-servers.org/ for more information.) At the time of this writing, four root servers have IPv6 addresses:
However, only B and M are reachable (for me). A closer look at the addresses used provides the following information:
The plot thickens... Since everyone and their little sister can easily obtain a /48 worth of IPv6 address space (I have two of those for personal use), it's expected that the global IPv6 routing table will suffer a lot of pollution from /48s, much like what happens with /24s in the IPv4 routing table, only worse. So it's unavoidable to filter on prefix length and not accept /48s.
(Additionally, it looks like the H /48 isn't announced at all: the route doesn't show up on the AMS-IX IPv6 looking glass, which does show the F /48 and other more specifics.)
When this issue came up on the IETF mailinglist, Paul Vixie, operator of the F root server, indicated that he had simply followed ARIN guidelines and obtained a /48 "micro allocation" from ARIN. It turns out ARIN has set aside a some address space for internet exchanges and "critical infrastructure". This address space is given out as /48s, see List of IPv6 Micro-allocations. (RIPE has a somewhat similar page at Smallest RIPE NCC Allocation / Assignment Sizes but it doesn't mention micro allocations.) All of this seems perfectly reasonable, except for one thing:
the existence of micro allocations is never mentioned in the RIR's IPv6 policy document.
This document, which is available in slightly different layouts and versions from LACNIC, APNIC, RIPE, ARIN and, for good measure, from IANA, says:
"4.3. Minimum Allocation
RIRs will apply a minimum size for IPv6 allocations, to facilitate prefix-based filtering.
The minimum allocation size for IPv6 address space is /32."
And this is exactly what many ISPs that offer IPv6 service do: they filter on a prefix length of 32 bits as indicated above, or 35 bits, the old allocation size. Obviously someone dropped the ball big time here, and this needs to be fixed in one way or another. Watch this space for more information. In the mean time, be sure to selectively relax your filters if you do prefix based filtering in IPv6. Gert Döring maintains a set of IPv6 BGP filter recommendations.
Permalink - posted 2003-12-09
I ran into two interesting articles at NetworkWorldFusion:
A while ago, they ran an article about BGP and BGP security under the title Fortifying BGP: No quick fix. The article doesn't go into much depth, but it has some interesting quotes. Fred Baker from Cisco says S-BGP is dead in the water, while S-BGP proponent Steve Kent at BBN speaks harsh words about Cisco's soBGP, indicating there are options in soBGP that are disastrous from a security standpoint and architectural problems. (The exact nature of the problems remains unclear, though.)
BGP Security at BGPexpert.com.
The other article, IPv6 fears seen unfounded, reports that early adopters find the transition to IPv6 both cheaper and easier to do than expected. Since the protocol has been in development for so long (8 to 10 years, depending on the IPv6 epoch of choice), most hardware and software vendors have now implemented the protocol so it's available (at no additional cost) now that people start adopting IPv6. Turning on the protocol turned out to be a fairly simple affair as well for the people quoted in the article.
Permalink - posted 2003-12-15
In an article earlier this year I talked about problems with path MTU discovery (PMTUD). (You may want to look at the links.) Quick recap:
One thing that many people may not realize is that the Cisco "no ip unreachables" directive turns off generation of ICMP "packet too big" or "fragmentation needed and DF bit set" messages for a router interface. ICMP messages have a type and a code. (IANA has the full list.) Type 3 covers different kinds of destination unreachable errors, including "packet too big" which is code 4 under type 3. Unfortunately, the Cisco documentation isn't particularly helpful. Under Configuring IP Services:
Enabling ICMP Protocol Unreachable Messages
If the Cisco IOS software receives a nonbroadcast packet destined for itself that uses an unknown protocol, it sends an ICMP protocol unreachable message back to the source. Similarly, if the software receives a packet that it is unable to deliver to the ultimate destination because it knows of no route to the destination address, it sends an ICMP host unreachable message to the source. This feature is enabled by default.
The fact that the ip unreachables command also affects sending of packet too big messages isn't even hinted at... The same goes for the description of the command in the command reference section. Only an ICMP Services Example explains a little more:
Disabling the unreachables messages will have a secondary effect—it also will disable IP Path MTU Discovery, because path discovery works by having the Cisco IOS software send Unreachables messages.
However, there still is no warning that disabling unreachables will make anything connected to links with reduced MTUs virtually unreachable, as nearly all hosts send all their packets with the DF bit set. And there are many people recommending "no ip unreachables": a Google search reveals this combination of words shows up, ironically, a little more than 1500 times.
There is a good use for this command, however: when a range of addresses is routed to the null interface, and "no ip unreachables" in configured for the null interface, any packets to the destinations in question will be dropped at the CEF level. Note that "no ip unreachables has affect on packets routed to the null interface, which is different from the behavior on other interfaces, where the command determines whether unreachables are sent back in response to packets received on the interface.
Most link types have a fairly fixed MTU (such as ethernet with its 1500 bytes) or support negotiation of the MTU (such as PPP). However, some link types make it very easy for both ends to set different MTUs. This regularly happens with Cisco's HDLC on serial links. In this case, the packets can't be received successfully at the end using the smaller MTU. Fortunately, debugging is easy: if the MTU is 1500, set it much higher, if it's larger than 1500, set it to 1500. In most cases this will clear up the problem. Or just switch to PPP... The same problem can happen on tunnels, but from what I've seen many systems just accept the too-large packets. This leads to strange path MTU discovery behavior as the link then has different MTUs in both directions, but this shouldn't be much of a problem.
I think the moral of this story is that it's probably not worth the trouble to run path MTU discovery on systems that have a 1500 byte MTU. Since all systems behind links that don't support 1500 bytes need to implement ugly hacks such as clearing the DF bit or rewriting the TCP MSS option anyway, the resulting increase in fragmentation on the network will be negligible and it should save significantly on debugging.
Can't get enough of fragments? Have a look at a CAIDA analysis.
Permalink - posted 2003-12-30