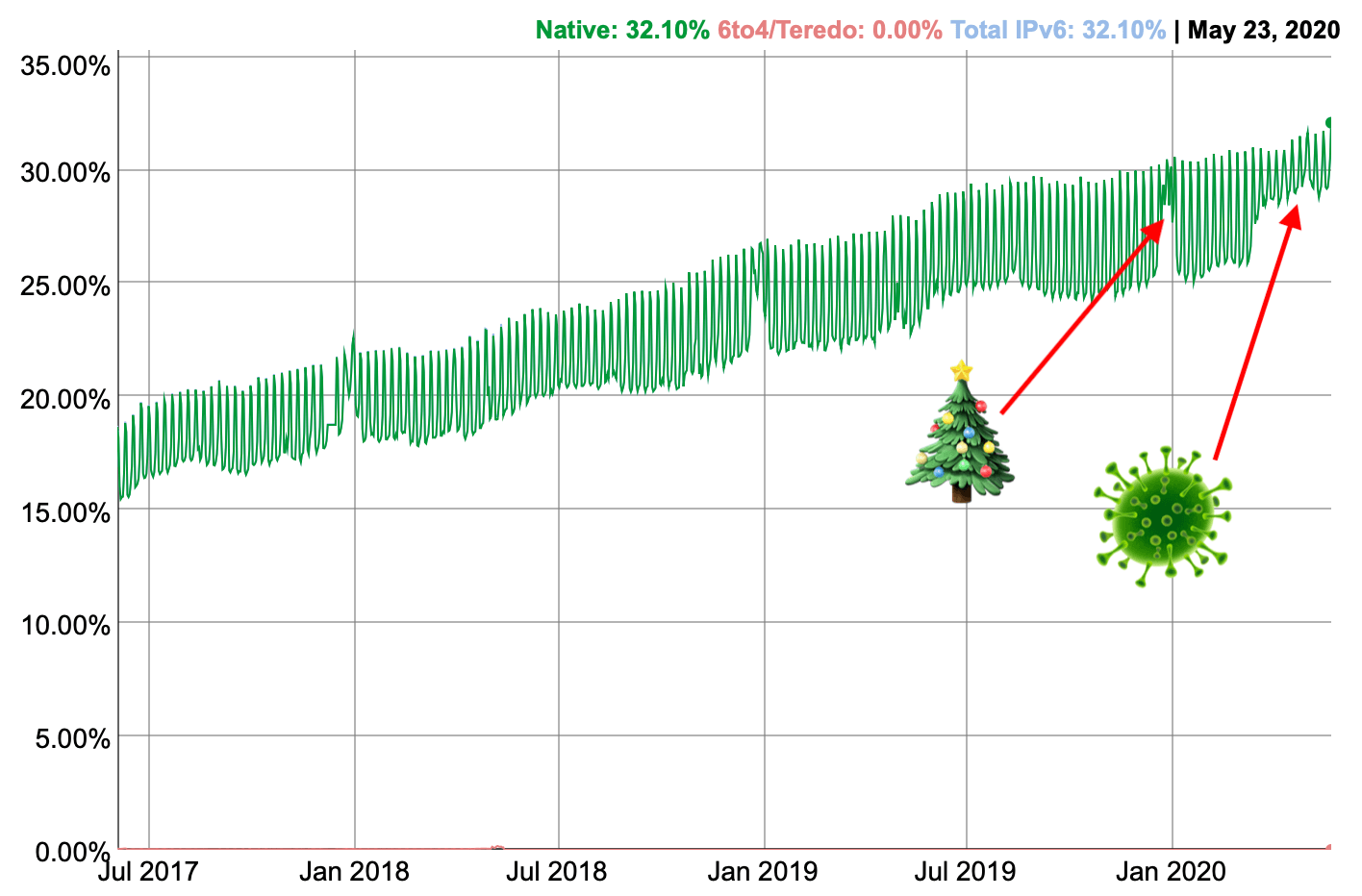
Turns out when it comes to IPv6 adoption, it is Christmas every day now:
Google's IPv6 statistics show that during the week, IPv6 adoption is about 5% lower than during the weekends, as apparently, more people have IPv6 at home than at work. Around Christmas, the minimum goes up while the maximum stays about the same.
In this regard the COVID-19 lockdown means it's Christmas every day: between December 20 and January 5, IPv6 adoption didn't drop below 27%. Between January 6 and March 13 there was no work day IPv6 adoption reached 28%, but since March 23, work day IPv6 adoption never dipped below 28%.
►
Recently, Cloudflare launched Is BGP safe yet?. And they immediately answer their own question: No.
What they're getting at is RPKI deployment. RPKI is a mechanism that lets the owner of a block of IP addresses specify which network gets to use those addresses. (Which AS gets to originate a prefix, in BGP speak.) RPKI protects to some forms of (mostly accidental) address hijacking. But for RPKI to work, the address owner needs to publish a "route origination authorization" (ROA) and networks around the globe need to filter based on these ROAs.
▼
Recently, Cloudflare launched Is BGP safe yet?. And they immediately answer their own question: No.
What they're getting at is RPKI deployment. RPKI is a mechanism that lets the owner of a block of IP addresses specify which network gets to use those addresses. (Which AS gets to originate a prefix, in BGP speak.) RPKI protects to some forms of (mostly accidental) address hijacking. But for RPKI to work, the address owner needs to publish a "route origination authorization" (ROA) and networks around the globe need to filter based on these ROAs.
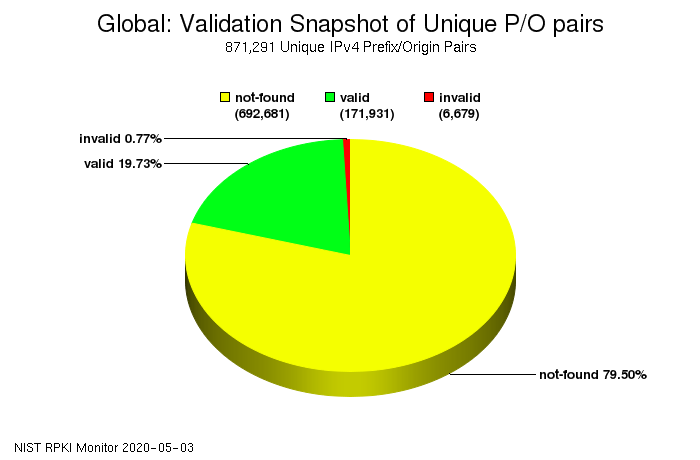
So globally, for just about 20% of all prefixes (address blocks) RPKI checks out (valid). For a little less than a percent, the way the address block is routed is not in agreement with the ROA (invalid). For the remaining nearly 80% of prefixes, no ROA is published (not-found). However, these numbers are different in various parts of the world:
North America: 9% valid, 0.3% invalid, 91% not-found
These numbers show how many address owners are publishing ROAs. This is very easy to do. Here in the RIPE region, it's just a few clicks in the LIR portal. The harder part is filtering based on RPKI. For this you need validator software, for which there are now several choices, and then you need to hook up the validator to your routers, explained here for Cisco and here for Juniper.
For some time, I feared networks would hesitate to filter out prefixes with the RPKI state "invalid", because there's still several thousand prefixes that are invalid. However, it now looks like there are enough big networks doing this that the onus of working around the resulting breakage is correctly put on the address owners / networks that cause the "invalid" state rather than the networks doing the filtering.
Is BGP safe yet? as well as a RIPE labs RPKI test tell you if your ISP is filtering RPKI invalid prefixes, with Cloudflare also naming and shaming the big ones that don't.
The RPKI Observatory has a list of prefixes that have the RPKI invalid state and are therefore unreachable with RPKI filtering enabled. The Route Views collector now also has RPKI, letting you check the state of individual prefixes (telnet route-views.oregon-ix.net). Or use the NLNOG RING looking glass.
Two weeks ago, I ordered a Mac Mini, my first desktop computer in 20 years. This is sort of a review of the Mac Mini, but I reserve the right to digress.
►
Back in 2013, I wrote a blog post about archiving. In it, I compared the costs per terabyte (and the weight per terabyte) of several ways to store data for archival purposes. When I read Beyond Time Machine: 5 Archiving over at The Eclectic Light Company blog, I realized that it’s time revisit this topic.
▼
Back in 2013, I wrote a blog post about archiving. In it, I compared the costs per terabyte (and the weight per terabyte) of several ways to store data for archival purposes. When I read Beyond Time Machine: 5 Archiving over at The Eclectic Light Company blog, I realized that it’s time revisit this topic. This is the list of storage options with the price per gigabyte in euros, back in 2013 and now in 2020:
€/TB 2013
€/TB 2020
Sweet spot
DVD±R
45
67
BR-R
45
2.5" USB HDD
60
23
4 - 10 TB
3.5" internal HDD
35
32
4 - 8 TB
USB flash
370
195
128 - 256 GB
SD card
520
320
128 GB
Internal SSD
125
1 TB
USB SSD
170
1 TB
And just to see how ridiculous things can get, if you buy an Apple computer, SSD upgrades can cost as much as € 1000 per terabyte (€ 250 to go from 256 to 512 GB).
The sweet spot is the size where the cost per terabyte is the lowest. If you go smaller or larger, you pay more for the same amount of storage. I got the 2020 prices by looking at bol.com. Obviously, prices vary, sometimes significantly. I chose the lowest prices, except if only a couple of no-brand options were the cheapest. Note that inflation was around 7% between 2013 and 2020.
What’s interesting here:
DVD±Rs have gone up in price
Blu-ray recordable is now at about the per-TB price DVD±R used to be
3.5" HDDs haven’t really gone down in price per TB
2.5" USB HDDs are now about three times cheaper than they used to be
2.5" USB HDDs are now a good deal cheaper than 3.5" HDDs
SSDs are still much more expensive than HDDs
2.5" USB HDDs are by far the cheapest way to archive your data. They’re also convenient: they’re small in size, and unlike 3.5" USB HDDs (which are extinct now, I think) they are bus powered so no issues with power supplies. Yes, copying terabytes worth of data to a USB HDD takes a lot of time. But you can do that overnight. With BD-Rs you need to put in a new one for every 25 to 100 GB.
I can still read most (but not all!) of the DVDs I burned 15 years ago without trouble, but I wouldn’t bet any money that a 15-year-old USB HDD will still work. You really have to keep your archived data on at least two of those and then replace them every three years or so, copying your data from the old one to a new one. (Or, more likely in my case: from my NAS to a new HDD.) But that’s a lot more doable than duplicating BD-Rs. Also, any computer can read USB HDDs, while for DVDs and blu-rays you need a drive, and those are much less common than they used to be, and that trend is sure to continue.
►
There's an episode of the TV show Friends where Chrissie Hynde has a guest role. Phoebe feels threatened by her guitar playing, and asks her "how many chords do you know?" "All of them."
Wouldn't it be cool if you could give the same answer when someone asks "how many programming languages do you know?"
But maybe that's a bit ambitious. So if you have to choose, which program language or programming languages do you learn?
▼
There's an episode of the TV show Friends where Chrissie Hynde has a guest role. Phoebe feels threatened by her guitar playing, and asks her "how many chords do you know?" "All of them."
Wouldn't it be cool if you could give the same answer when someone asks "how many programming languages do you know?"
But maybe that's a bit ambitious. So if you have to choose, which program language or programming languages do you learn? I got started with BASIC, 6502 assembly, Forth and Pascal. Those are now all obsolete and/or too niche. These are other languages that I'm familiar with that are relevant today:
C
Javascript
Python
PHP
I'd say that either C or Javascript is the best choice as a first language to learn. Javascript has the advantage that you only need a web browser and a text editor to get started, and you can start doing fun and useful things immediately. However, Javascript's object orientation and heavy use of events makes it hard to fully understand for someone new to programming. So it's probably better to dip a toe in with Javascript and after a while start learning another language to get a better grasp of the more advanced fundamentals.
C is the opposite of Javascript. It's certainly not very beginner friendly, not in the least because it requires a compiler and a fair bit of setup before you can start doing anything. And then you get programs that run from the command line. It's much harder to do something fun or useful in C. However, what's great about C is that it's relatively simple and low level, which means that it's an excellent way to learn more about the way computers and data structures actually work. Because it's a simple language, it's a reasonable goal to learn the entire language. That's especially important when reading other people's code. Also, many other languages such as Java, Javascript and PHP are heavily influenced by C, so knowing C will help you understand other languages better.
If you want to be able to be productive as a programmer and you could only use one language, Python is probably the one. It's used for many different things and has some really nice features to help you start going quickly. But it also has many of its own quirks and complexity hides just below the surface, so like with Javascript, I would use Python as a "dipping your toe in" language and if you want to learn more, switch to something else. A big advantage of Python over C is that you don't need a compiler, but it still (mostly) lives on the command line.
PHP is the language that I've used the most over the last 20+ years. If that hadn't been the case, I'm not sure it would have been on this list. It's not held in very high regard in many circles, so if you want something that looks good on your CV, PHP is not a top choice. Then again, it works very well for web backends, and has an incredible amount of stuff built in, allowing you to be productive quickly. It's also close to C in many ways, so that helps if you already know C. But like Javascript and Python it's a dynamic language, so it takes a lot less work to get things done than in C.
Of course a lot depends on what you want to do. For stuff running in a browser, Javascript is the only choice. For low level stuff, C is the best choice, although Python could work in some cases, too. I think for web backends, PHP is the best fit, but Python can certainly also do that. For developing mobile apps, you need Swift or Objective C. For Android, Java or Kotlin. Mac apps are also generally in Objective C, with Swift (Apple's relatively new language) becoming more common. On Windows, a lot of stuff is written in C#. A lot of lower-level stuff, especially graphics, is done in C++. So these are all very useful languages, but I wouldn't recommend any of them as a first language.
So let's have a look at a simple program in each of those languages, and then see how fast they run that same program. For a given input, the program calculates what numbers that input is divisible by. (It's not optimized in any way and there is no error checking, so it's not an example of good code.)
C:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int n, i;
n = atoi(argv[1]);
if (n % 2 == 0)
printf("%d\n", 2);
for (i = 3; i < n; i += 2)
if (n % i == 0)
printf("%d\n", i);
}
PHP:
<?php
$n = $argv[1];
if ($n % 2 == 0)
printf("%d\n", 2);
for ($i = 3; $i < $n; $i += 2)
if ($n % $i == 0)
printf("%d\n", $i);
Javascript:
<script lanugage=javascript>
var ts1, ts2, n, i;
ts1 = new(Date);
n = 444666777;
if (n % 2 == 0)
document.write(2 + "<br>\n");
for (i = 3; i < n; i += 2)
if (n % i == 0)
document.write(i + "<br>\n");
ts2 = new(Date);
document.write("Time: " +
(ts2.getTime() - ts1.getTime()) / 1000 +
" seconds<br>\n");
</script>
Python:
import sys
import math
n = int(sys.argv[1])
if (n % 2 == 0):
print(2)
for i in range(3, n, 2):
if (n % i == 0):
print(i)
(For the Javascript version I hardcoded 444666777 as the input, for the others the input is read from the command line.)
Common wisdom is that compiled languages like C are faster than interpreted languages (the others). That turns out to be true, with the C version (compiled with -O3 optimizations) taking 0.7 seconds on my 2013 MacBook Pro with a 2.4 GHz Intel i5 CPU.
But interestingly, the Javascript is barely any slower at just over 1 second. This shows just how much effort the browser makers have poured into making Javascript faster.
The PHP version, on the other hand, takes more than 21 seconds. The Python version 50 seconds. Weirdly, 15 of those seconds were spent running system code. This is because running the Python program uses up 6 GB of memory on my 8 GB system, so the system has to do all kinds of things to make that work.
It turns out that having a for loop with the range function is problematic. It looks like range first creates the requested range of numbers in memory (all 222 million of them!) and then the for loop goes through them. But we can replace the for loop with a while loop:
import sys
import math
n = int(sys.argv[1])
if (n % 2 == 0):
print(2)
i = 3
while (i < n):
if (n % i == 0):
print(i)
i = i + 2;
This does the same thing, but in a way that's more like the for loops in the other languages. This version takes 36 seconds, and, more importantly, there are no issues with memory use.
C can do these calculations really fast because the overhead of pushing many small instructions to the CPU is small. Each instruction has more overhead in the other languages. With more complex operations, such as manipulating text strings, the C's advantage is a lot less because each operation in the program leads to a much larger number of instructions for the CPU, so the language overhead is a much smaller part of the running time. I haven't been able to think of a nice simple test program to see how big the difference is, though.
Like other very successful protocols such as HTTP and DNS, over the years BGP has been given more and more additional jobs to do. In this blog post, we’ll look at the new functionality and new use cases that have been added to BGP over the years. These include various uses of BGP in enterprise networks and data centers.
Recently, I've been looking a bit at BGP in datacenters, and it's really interesting to see how BGP is used in such different ways than it is for global inter-domain routing.